Git Tutorial - Working with Branches
Starting with this section, the tutorial covers a few advanced topics related to working with Git, mostly related to how to work collaboratively with other students on the same Git repository. If you have been working through the tutorial for a class that only requires you to work individually with your repository, you may not need to read the following sections (if in doubt, check with your instructor).
The following sections assume that you have worked through the previous sections of the Git tutorial or are already familiar with the topics covered in the earlier parts of the tutorial. If you did not work through them but are comfortable with the material covered in it, make sure to create a repository on GitHub with just a README in it, as you will need it to work through this tutorial.
Working collaboratively with Git
Suppose you are working with a classmate on a homework assignment that
requires producing a single file called hw1.c that includes the
implementation of some functions. If the file is located in a shared
filesystem (like the CS filesystem where the same home directories
appear on all the CS machines), the two of you could edit it at the same
time, but you’d have to be careful not to overwrite each other’s work.
For example, suppose you both open the file and it contains the following:
int foo()
{
// Write your code here
}
You decide to work on function bar() and your partner decides to
work on function baz(). So, you end up with this file:
int foo()
{
// Write your code here
}
int bar()
{
// ...
}
And your partner ends up with this:
int foo()
{
// Write your code here
}
int baz()
{
// ...
}
If you save the file, and then your partner saves it after you, their
version of the file will overwrite yours, so all your work on bar()
will be overwritten.
Ideally, we would like to end up with a consolidated version of the file that looks like this:
int foo()
{
// Write your code here
}
int bar()
{
// ...
}
int baz()
{
// ...
}
Of course, instead of using a shared filesystem, you could instead decide that only one person can edit the file at a time, but that would involve a lot of overhead in coordinating each other’s work.
Consider this other scenario: let’s say that the foo() function
involves implementing two sub-tasks, which you divide amongst
yourselves, and you each replace the // Write your code here with
your code (for the sake of simplicity, let’s assume that each sub-task
is implemented with a single printf). Your code might look like
this:
int foo()
{
printf("Implemented task 1\n");
}
And your partner’s code might look like this:
int foo()
{
printf("Implemented task 2\n");
}
This actually represents a conflict in your code: you each have
divergent replacements for the // Write your code here line, and it
is not clear which version is the correct one. In fact, while there may
be cases where we simply want to use one version over another, in this
case we would like to merge these two versions together to produce
something like this:
int foo()
{
printf("Implemented task 1\n");
printf("Implemented task 2\n");
}
Notice how, earlier, there was no conflict when implementing bar()
and baz() because you were adding code to hw1.c, instead of
replacing existing code with different versions.
Version control systems like Git are very useful when dealing with scenarios like the ones above. They will allow two (or more) developers to work concurrently on the same code and, whenever possible, will automatically merge together changes that do not conflict. When a conflict does arise, Git provides a specific mechanism to resolve that conflict, which we discuss in the following sections.
Branches
So far, the commits in your tutorial repository have created a linear sequence of changes like this:
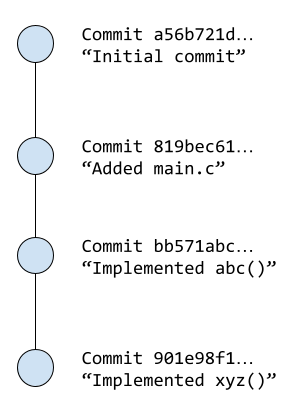
This is known as the main branch of your repository (Git itself uses
the name master by default, but GitHub uses the name “main”).
But, what
is a “branch”? A branch, loosely, is an
independent commit history than can be manipulated in its own right.
So far, you have been working with only one branch (the main branch) and,
thus, with a single linear history of commits.
However, Git (and most version control systems) allow you to create multiple branches. These branches are not completely independent of each other as, ordinarily, a branch must be “branched off” from an existing commit. So, for example, we could have the following:
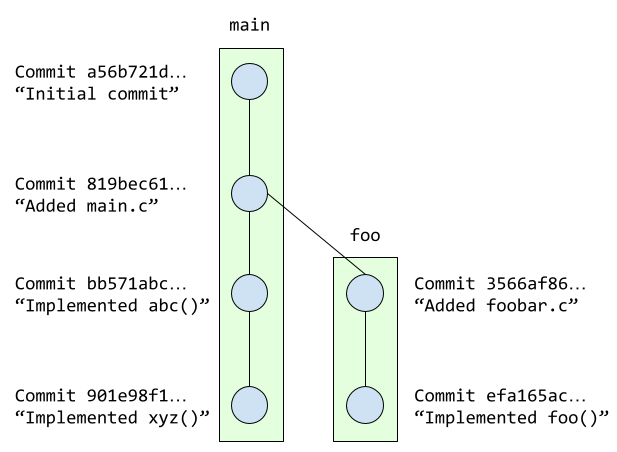
Here, besides the main branch, we have an additional foo branch
which could be used to work on a separate feature of a project (or, in this
case, on an additional foobar.c file where we are implementing a foo()
function). This
separate branch allows us to work on this task independently from other
tasks; this may seem over-complicated, but suppose you were working on
a homework or project with a classmate: branches would allow you to work independently
without having to step on each other’s toes. This is similar to the
first example we showed above (where two developers could be working on
separate functions, bar() and baz()).
To experiment with branches, start by adding a file called echo.c
to your repository, with the following contents:
/* echo.c - echo user input */
/* [AUTHOR GOES HERE] */
/* Last updated: 3/28/22 */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(){
char input[500];
while(fgets(input, 500, stdin)){ //read from STDIN (aka command-line)
printf("%s\n", input); //print out what user typed in
memset(input, 0, strlen(input)); //reset string to all 0's
}
return 1;
}
Make sure to add, commit, and push the file:
$ git add echo.c
$ git commit -m "Added echo.c"
$ git push
Now, let’s create a new branch in your repository. The
branch will be called add-author and you can create it by running
this:
$ git checkout -b add-author
If you run git branch, you can see the list of branches in the
repository, with the current branch highlighted with an asterisk:
* add-author
main
The current branch of a local repository is the branch where any new
commits will be added to. Remember, a single branch is a linear sequence
of commits and, when we have multiple branches (as shown in the diagram
above), a commit could be placed after the last commit, or head, of
any branch. The head of the current branch is referred to as the
HEAD (in all caps) of the repository.
You can switch the current branch by using the git checkout command.
For example:
$ git checkout main
Switched to branch 'main'
Your branch is up to date with 'origin/main'.
$ git branch
add-author
* main
$ git checkout add-author
Switched to branch 'add-author'
$ git branch
* add-author
main
Now, let’s add a commit to the add-author branch. Simply edit the
echo.c file and replace [AUTHOR GOES HERE] with your name. Let’s
add and commit this change:
$ git add echo.c
$ git commit -m "Updated author in echo.c"
Now, let’s try to push this change. We’ll actually be prevented from doing so:
$ git push
fatal: The current branch add-author has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin add-author
This means the push has not been completed. The reason for this is that we haven’t told Git where to push this new branch (it will not assume that it has to be pushed to the GitHub repository). Fortunately, you can resolve this issue simply by running the verbatim command provided in the error message:
$ git push --set-upstream origin add-author
Enumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 16 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 367 bytes | 367.00 KiB/s, done.
Total 3 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
remote:
remote: Create a pull request for 'add-author' on GitHub by visiting:
remote: https://github.com/GITHUB_USERNAME/uchicago-cs-git-tutorial/pull/new/add-author
remote:
To git@github.com:GITHUB_USERNAME/uchicago-cs-git-tutorial.git
* [new branch] add-author -> add-author
Branch 'add-author' set up to track remote branch 'add-author' from 'origin'.
Note: You should ignore the “pull request” instructions in the above message.
If you now go to your repository on GitHub,
and click on the “Branch” pull-down list, you will see add-author in
the list of branches.
Please note that, from this point onwards, you’ll be able to push this
new branch just by running git push (the --set-upstream option
is only necessary the first time you push a new branch)
Merging
The main branch is, by convention, the “stable” branch of the
repository, in the sense that it should only contain stable (not broken)
code. So, it is very common to create separate branches to implement
specific tasks, features, etc. and to then merge them back to the
main branch once that work is finished. This keeps the main
branch much cleaner, as it only contains the “final” version of our code
at any point, instead of lots of commits that may represent work in
progress.
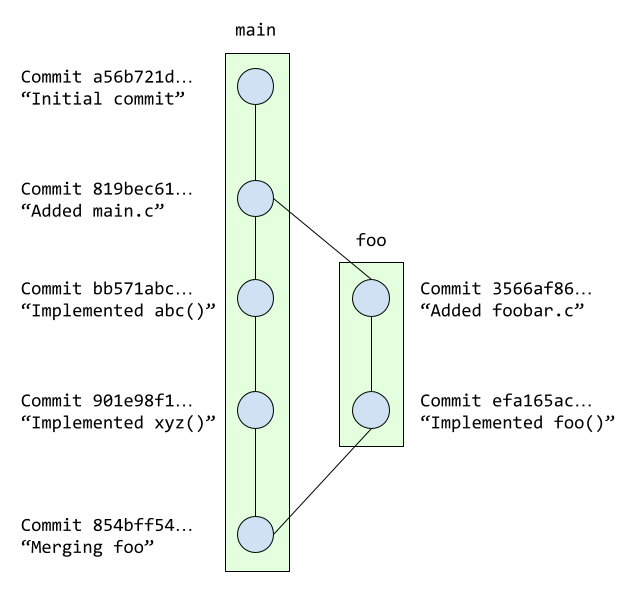
When we merge a branch with another branch, we basically take all the
changes done in all the commits in the origin branch, and add them to
the destination branch. This is done by creating a new commit, called a
merge commit, to merge together the heads of the two branches. For
example, in this diagram, commit 854bff54 merges foo into
main:
Now, let’s say we want to merge the changes from our add-author branch into
the main branch. We first need to switch to the main branch:
$ git checkout main
Then, we use git merge to specify that we want to merge
add-author into the current branch (main):
$ git merge add-author
If the merge works, you should see the following:
Updating 2a78570..a893dc8
Fast-forward
echo.c | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
You should open echo.c to verify that the merge was completed
successfully.
However, if you run git log, you won’t see any special “merge
commit” in the log history:
commit a893dc8d2843b1f00f1f083cf7a32931aaef909e (HEAD -> main, add-author)
Author: Borja Sotomayor <borja@cs.uchicago.edu>
Date: Sat Mar 27 11:08:21 2021 -0500
Updated author in echo.c
commit 2a7857065581a0c003418c308cd0330b1021d32d (origin/main)
Author: Borja Sotomayor <borja@cs.uchicago.edu>
Date: Sat Mar 27 11:00:12 2021 -0500
Wrapping up first part of the tutorial
commit 6b336a1d68b868da708c38bf3e1683155ae2967f
Author: Borja Sotomayor <borja@cs.uchicago.edu>
Date: Sat Mar 27 10:53:21 2021 -0500
Added echo.c
The reason for this is that this was a fairly trivial merge which could
be fast-forwarded, because the commit in add-author
(Updated author in echo.c) descends directly from the
Added echo.c commit in main, so we can simply take
that commit and add it to main.
Before continuing, make sure to push the changes we just
made to the main branch:
$ git push
Merge conflicts
Things get a bit trickier if we try to merge branches where
the code has diverged in some way. For example, let’s create
a new branch called update-buffer-size:
$ git checkout -b update-buffer-size
Now, update echo.c so the size of the input array is 1000
instead of 500 (similarly, update the second parameter to fgets
accordingly).
Let’s commit and push this change:
$ git add echo.c
$ git commit -m"Updated buffer size to 1000"
[update-buffer-size a72bbd0] Updated buffer size to 1000
1 file changed, 2 insertions(+), 2 deletions(-)
$ git push --set-upstream origin update-buffer-size
Total 0 (delta 0), reused 0 (delta 0)
remote:
remote: Create a pull request for 'update-buffer-size' on GitHub by visiting:
remote: https://github.com/GITHUB_USERNAME/uchicago-cs-git-tutorial/pull/new/update-buffer-size
remote:
To git@github.com:GITHUB_USERNAME/uchicago-cs-git-tutorial.git
* [new branch] update-buffer-size -> update-buffer-size
Branch 'update-buffer-size' set up to track remote branch 'update-buffer-size' from 'origin'.
Now, let’s switch to the main branch:
$ git checkout main
The buffer size in echo.c will still be 500. Let’s make a change
that will conflict with the change we made on a separate branch:
change the buffer to 250, and commit that change:
$ git add echo.c
$ git commit -m "Updated buffer size to 250"
[main e5ec414] Updated buffer size to 250
1 file changed, 2 insertions(+), 2 deletions(-)
So, we’re now in a situation where the main branch and the update-buffer-size
branches have each made conflicting changes to the same lines. While we’ve artificially
created this situation, take into account that this can easily happen in a project
with multiple developers: one developer could decide to change the buffer size to
1000, while another decides that 250 is enough.
Let’s see what happens if we try to merge update-buffer-size:
$ git merge update-buffer-size
Auto-merging echo.c
CONFLICT (content): Merge conflict in echo.c
Automatic merge failed; fix conflicts and then commit the result.
Git has detected a merge conflict! A merge conflict is basically Git telling us “I see two conflicting changes on these two branches, and I don’t know how to resolve them automatically; you need to tell me how to do it”.
Merge conflicts will also be shown on git status:
$ git status
On branch main
Your branch is ahead of 'origin/main' by 1 commit.
(use "git push" to publish your local commits)
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: echo.c
no changes added to commit (use "git add" and/or "git commit -a")
If you open echo.c, you will see something like this:
int main(){
<<<<<<< HEAD
char input[250];
while(fgets(input, 250, stdin)){ //read from STDIN (aka command-line)
=======
char input[1000];
while(fgets(input, 1000, stdin)){ //read from STDIN (aka command-line)
>>>>>>> update-buffer-size
printf("%s\n", input); //print out what user typed in
memset(input, 0, strlen(input)); //reset string to all 0's
}
return 1;
}
In general, any time you see something like this:
<<<<<<< branch1
=======
>>>>>>> branch2
This is Git telling you “this is the version of the code in branch
branch1 and the version of the code in branch2; tell me which
one to use”.
In some cases, resolving the merge conflict will involve editing the file to keep the exact version from one of the two branches. In a graphical code editor, you may not even have to edit the file, and may encounter a convenient interface asking you which of the two versions you’d like to keep.
However, we are not required to resolve the merge conflict by choosing one of the two versions. For example, the developer handling this merge conflict may look at this and realize that the buffer size should actually be 300. In that case, we would just replace this:
<<<<<<< HEAD
char input[250];
while(fgets(input, 250, stdin)){ //read from STDIN (aka command-line)
=======
char input[1000];
while(fgets(input, 1000, stdin)){ //read from STDIN (aka command-line)
>>>>>>> update-buffer-size
with this:
char input[300];
while(fgets(input, 300, stdin)){ //read from STDIN (aka command-line)
i.e., the full echo.c file should look like this:
/* echo.c - echo user input */
/* YOUR_NAME */
/* Last updated: 3/28/22 */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(){
char input[300];
while(fgets(input, 300, stdin)){ //read from STDIN (aka command-line)
printf("%s\n", input); //print out what user typed in
memset(input, 0, strlen(input)); //reset string to all 0's
}
return 1;
}
Now, we need to tell Git that we’ve resolved the merge conflict. We do
this by using git add:
$ git add echo.c
Note how now git status recognizes that the merge conflict has been
resolved, but has yet to be committed:
$ git status
On branch main
Your branch is ahead of 'origin/main' by 1 commit.
(use "git push" to publish your local commits)
All conflicts fixed but you are still merging.
(use "git commit" to conclude merge)
Changes to be committed:
modified: echo.c
So, all we need to do is to run this command:
$ git commit
This will open up an editor with a default commit message like
Merge branch 'update-buffer-size' into main. You could change this
to something like Merging 'update-buffer-size' (buffer should actually be 300)
to indicate that you did not actually accept the changes from the update-buffer-size
branch but, for the purposes of this tutorial, you can also just use the default message.
Once you save the commit message, the merge will be completed and you will see something like this:
[main e58a1ba] Merge branch 'update-buffer-size' into main
That is the merge commit for this merge; if you run git log, you
will see that the commit history now includes the commit from
update-buffer-size, as well as the merge commit. Notice how it includes a
Merge: line telling us which two commits were merged:
commit e58a1baa2d6d408027a04d19ca322ef4ceaae9da (HEAD -> main)
Merge: e5ec414 a72bbd0
Author: Borja Sotomayor <borja@cs.uchicago.edu>
Date: Sat Mar 27 11:25:43 2021 -0500
Merge branch 'update-buffer-size' into main
commit e5ec414fb5422487f3d0469583461c9a260432d9
Author: Borja Sotomayor <borja@cs.uchicago.edu>
Date: Sat Mar 27 11:15:04 2021 -0500
Updated buffer size to 250
commit a72bbd0ee5302906177cc9f62d4ff55e1a02c999 (update-buffer-size)
Author: Borja Sotomayor <borja@cs.uchicago.edu>
Date: Sat Mar 27 11:12:57 2021 -0500
Updated buffer size to 1000